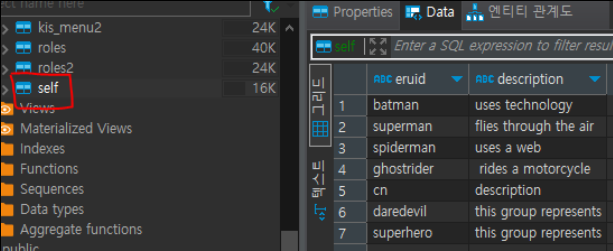
개발 서버에서 Spark를 사용하여 위의 파이프라인 데모를 구성했습니다.
Spark(PySpark)를 통해 특정 파일 확장자(CSV, JSON 등)를 RDB에 저장합니다.
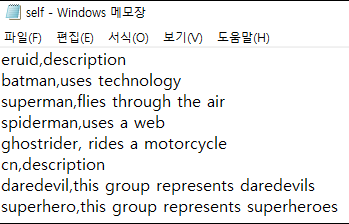
> 샘플 파일
file_to_postgres
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StructField, StringType, IntegerType
from pyspark.sql.types import ArrayType, DoubleType, BooleanType
from pyspark.sql.functions import col,array_contains
ip = "10.65.41.141"
port = 5432
user = "isharkk"
passwd = "rplinux"
db = "testt"
spark = SparkSession \
.builder \
.appName('SparkByExamples.com') \
.config("spark.driver.extraClassPath", "/root/spark-3.2.2-bin-hadoop3/jars/postgresql-42.5.4.jar") \
.getOrCreate()
df = spark.read.csv("file:///root/self.csv")
df2 = spark.read.option("header",True) \
.csv("file:///root/self.csv")
df_with_schema.printSchema()
df2.write.option("header",True) \
.csv("/tmp/spark_output/self.csv")
query1 = df2.write.format("jdbc")\
.option("url","jdbc:postgresql://{0}:{1}/{2}".format(ip, port, db)) \
.option("driver", "org.postgresql.Driver") \
.option("dbtable", "ishark.self") \
.option("user", user) \
.option("password", passwd) \
.save()
> CSV 파일의 해당 스키마 속성

> 적절한 CSV 파일 헤더 형식 추가
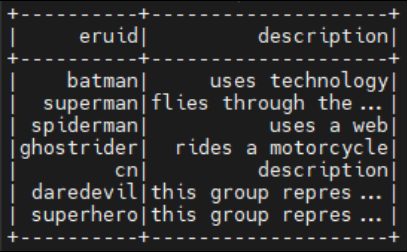
> PostgreSQL에 로드된 CSV 데이터